
原文地址:https://blog.bitsrc.io/server-side-caching-in-expressjs-24038daec102
作者:Chidume Nnamdi
缓存已经是在软件开发过程中被广泛应用的技巧之一。在这篇文章中,我们将看看如何在 express 服务端启用缓存。
服务端缓存-基本理念
Web 应用通常在服务端获取新数据然后在 DOM 中渲染。这给服务器带来了大量的负担,因为它需要大量的处理能力取产生动态数据。浏览器端利用缓存来防止频繁的请求。浏览器有内部缓存机制来允许在相同的请求发生时存储请求的响应并且用缓存的响应数据来响应请求。这有助于防止来自相同请求的频繁服务器操作。
虽然浏览器有帮助,但是服务器需要为不同的浏览器和用户运行和渲染。服务器端必须找到一种优化长操作的方法。这已经可以通过运用缓存来做到了。
什么是缓存?
在我们开始探究服务器缓存之前先让我们明白什么是缓存?
缓存的概念是存储 CPU 密集型操作的结果,以便在下次执行具有相同输入同样的操作时,结果从储存中返回而不是重新执行消耗资源的操作。
在编程中,函数通常被缓存,这个过程称为记忆化。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19function longOp(input) {
let result = null
// simulating a long operation using setTimeout
setTimeout(()=> {
console.log('done with longOp func')
result = 90 * input
}, 1000)
return result
}
longOp(5) // takes 1000 ms to complete
longOp(50) // takes 1000 ms to complete
longOp(500) // takes 1000 ms to complete
longOp(5000) // takes 1000 ms to complete
// Total ms to run: 4000 ms!
longOp(5) // takes 1000 ms to complete
longOp(50) // takes 1000 ms to complete
longOp(500) // takes 1000 ms to complete
longOp(5000) // takes 1000 ms to complete
// Total ms to run: 4000 ms! again
以上函数运行花了1000ms,我们试着用不同的输入调用它:5,50,500,5000。我们的文件总共花了4000ms去运行。再次运行相同的输入将同样需要4000ms。
现在,因为我们知道输出依赖输入 return input*90。我们可以储存每一次输入产生的结果,并且在下一次同样输入调用时返回。
1 | function longOp(input) { |
现在我们在 loogOp 函数中加入了缓存。缓存对象是我们为每一次输入储存计算结果的地方。当函数被调用,我们检查缓存对象中是否有结果,如果有我们将跳过一个长操作并返回结果,如果没有,我们执行长操作并将结果存到缓存中,用输入作为 key 值,这样在下一次同样输入的函数调用中,我们可以在缓存中找到相应结果并返回。
如果我们再次运行loogOp:1
2
3
4
5
6
7
8
9
10longOp(5) // takes 1000 ms to complete
longOp(50) // takes 1000 ms to complete
longOp(500) // takes 1000 ms to complete
longOp(5000) // takes 1000 ms to complete
// Total ms to run: 4000 ms!
longOp(5) // takes 1 ms to complete
longOp(50) // takes 1 ms to complete
longOp(500) // takes 1 ms to complete
longOp(5000) // takes 1 ms to complete
// Total ms to run: 4 ms! again :)
您看,这是一个巨大的性能提升。从4000ms到4ms,第一次运行没有缓存,第二次运行仅仅从缓存中返回了第一次运行的结果。
现在,我们已经明白了缓存的意义,让我们继续。
Tips:用Bit 在项目之间共享组件,并且可以更快的构建JS应用。这是从repo共享包并且使用他们的最快的方法。
我们经历了相同的事情,当我们在用 express.js :一个快速搭建服务的 Node.js 框架。假设我们有一个像这样的索引路径:1
2
3
4
5
6app.get('/', (req, res) => {
// simulating a long process
setTimeout(()=>{
res.send('message from route /')
}, 1000)
})
我们在这里有一个路由,它将会返回 message from route /消息,我们使用setTimeout模拟一个缓慢的进程。这就好比如果我们是一个新闻网站服务器API,我们生成近千条新闻。这将花费近1000ms来为我们的用户交付新闻负载。
来试试这个,新建一个 Node 项目并且安装 express 模块:1
2
3
4
5mkdir expr-cache-prj
cd expr-cache-prj
npm init -y
npm i express
touch index.js
将下面的内容粘贴到 index.js 文件中:1
2
3
4
5mkdir expr-cache-prj
cd expr-cache-prj
npm init -y
npm i express
touch index.js
在命令行中运行node ./来启动服务:1
2node ./
server:3000
打开您最喜爱的浏览器并导航到localhost:3000。打开开发者工具并切换到 Network 面板。
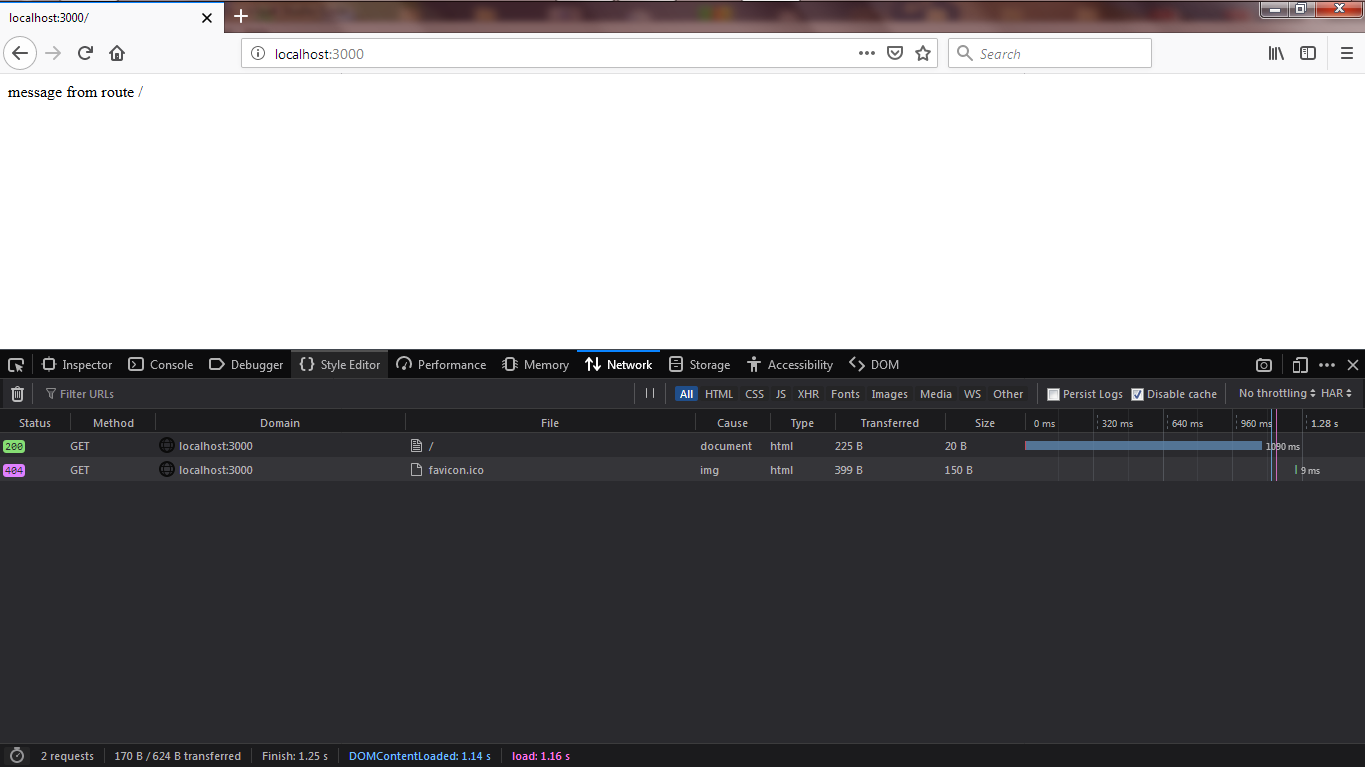
您可以在 timeline 面板中看到渲染路由大约花费了1090ms,因为1000ms 花在了服务响应,剩下的90m花在了将 message 内容渲染。您了解服务器如何影响我们 Web 应用的性能。优化不仅仅是在客户端的,服务器的优化更为重要。如果您的服务器端应用需要1000毫秒来发送客户端将采用的数据(1000 + 0.000001)1000.000001毫秒进行渲染,那么优化客户端甚至可以达到0.000001毫秒。
如果我们将时间增加到9000ms:
1 | app.get('/', (req, res) => { |
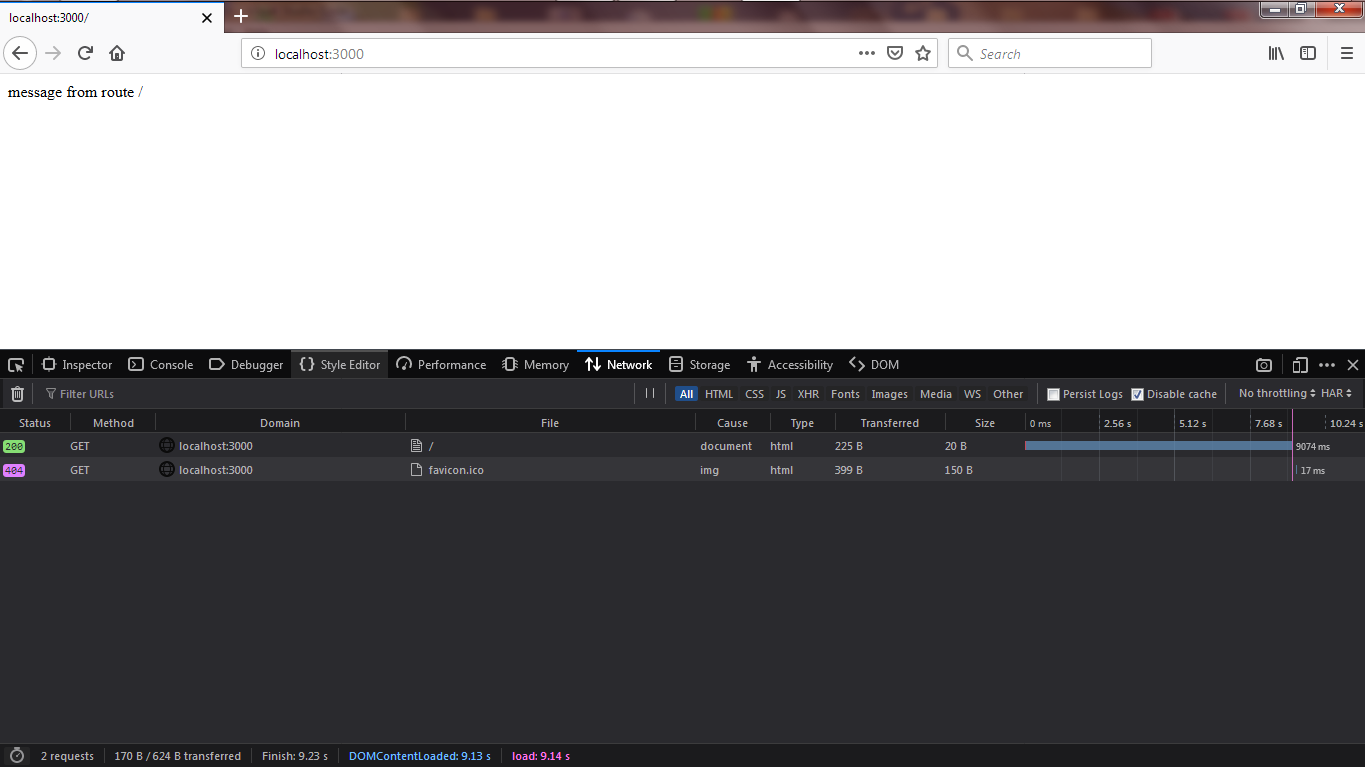
在这里消息渲染花费了9074ms,在这9074ms中,服务器发送消息花费了9000ms。
现在让我们看看使用缓存的 express 的不同技术:
使用自定义缓存技术
在 express 中,中间件是添加缓存的理想方式。
1 | const middleWare1 = (req,res,next)=> { |
当路由被访问时,express 调用middleWare1,middleWare1 调用next ,express 调用下一个中间件 middleWare2,middleWare2 调用 next,然后因为没有更多的中间件内联执行退出。
1 | expressjs |
一般来说,我们在最后一个中间件里将数据发送给用户。1
2
3
4
5
6
7const middleWare1 = (req, res, next) => {
next()
}
const middleWare2 = (req, res, next) => {
res.send('expressjs data')
}
app.get(route, middleWare1, middleWare2)
如果我们在 middleWare1 中添加中间件,我们会看到完美的配合。它将会首先运行,所以我们要检查路由是否被缓存。如果是,我们会从 middleWare1 发送缓存结果,如果不是,我们将冒泡到 middleWare2.
在我们 /路由中:1
2
3
4
5app.get('/', (req, res) => {
// simulating a long process
wait(1000)
res.send('message from route /')
})
我们将添加一个中间件来保存我们的缓存代码。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18var cache = {};
var middware = (req,res,next)=>{
const key = req.url;
if(cache[key]) {
res.send('from cache');
} else {
res.sendResponse = res.send;
res.send = (body)=>{
cache[key] = body;
res.sendResponse(body);
}
next();
}
}
app.get('/',middleware,(req,res)=>{
wait(1000);
res.send('message from route /');
})
我们创建了中间件 middleware。我们创建了存放缓存结果的对象。在 middleware 函数中,我们用请求的路径作为键。首先我们检查基于请求的路径的 key 在缓存对象中是否存在。如果是,我们发送从缓存中发送响应,如果没有,我们在缓存对象中储存请求体并且发送响应以便下一次请求可以直接提取缓存数据。
如果我们在服务端运行以上代码,我们将在浏览器中看到改进:
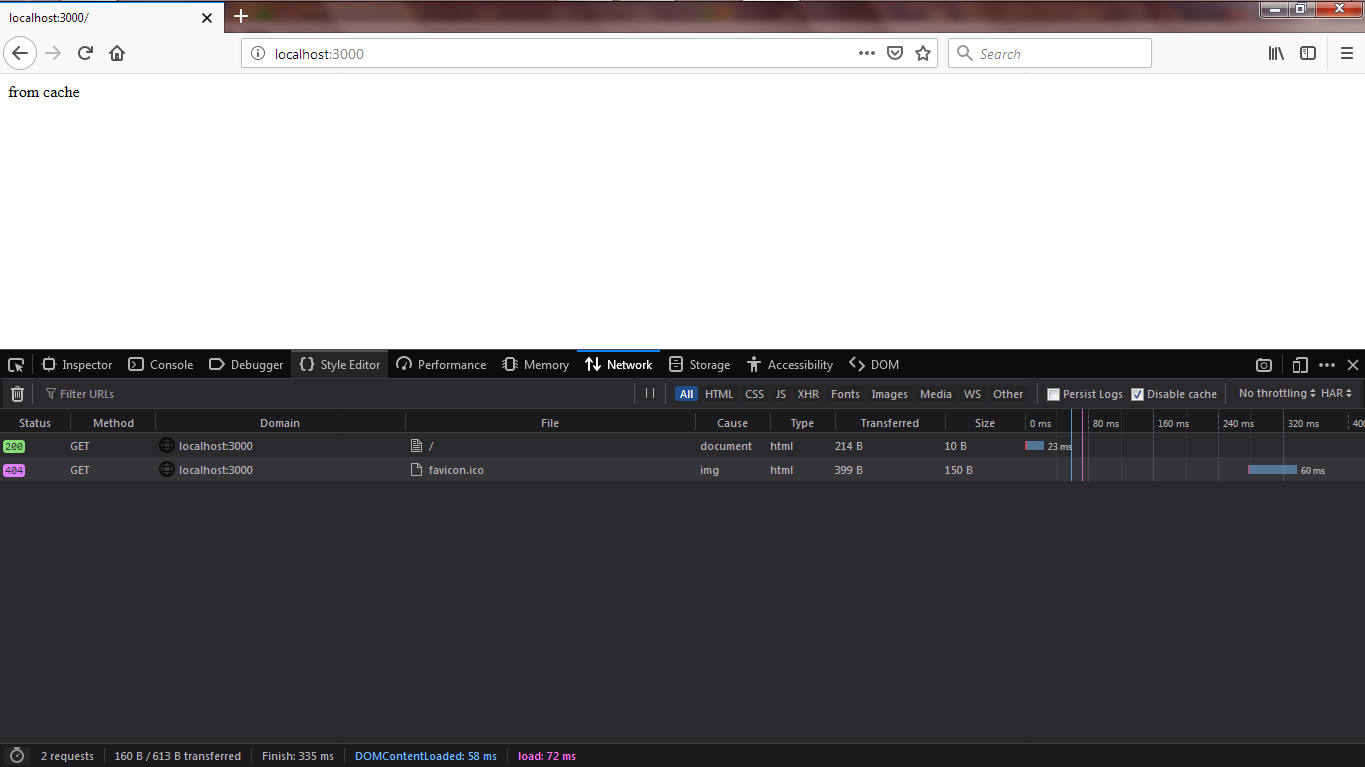
看到了没,浏览器花了23ms来渲染。是我们上一次的一半多。
我们已经明白来怎么在 express 服务中添加缓存。我们上面做的有以下缺点:
- 我们将缓存存储在进程中,一旦我们的服务挂掉,我们将从头开始缓存。
- 缓存不能在同一进程中多数服务中共享。
NB 缓存在get类型路由是可行的,但是不能用在 put,delete,post 路由中。当输出依赖与输入时,在get路由才能添加缓存。get路由副作用永远不应该被缓存,因为输出会随着时间而变化。
采用Redis
Redis是一个非传统数据库,被称为数据结构服务器。它可以在内存中以极快的速度运行。
Redis 在内存存储数据方面非常强大,我们可以在我们的应用中用它做数据缓存或者数据库。它主要的AIP由set(key,value)和get(key)组成。为了在我们已有的应用中整合 Redis,我们开始安装Redis模块。
首先,我们安装Redis npm 模块:1
npm i redis
现在,我们创建了一个 Redis 模块并且和 Redis 服务建立了🔗。1
2const redis = require('redis');
const client = redis.createClient()
我们像这样编辑 exp.js:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29const redis = require('redis');
const client = redis.createClient()
client.on('connect',()=>{
log('redis connected')
})
const app = express();
const log = console;
var midWare = (req, res, next) => {
const key = req.url
client.get(key, (err, result) => {
if (err == null && result != null) {
res.send('from cache')
} else {
res.sendResponse = res.send
res.send = (body) => {
client.set(key, body, (err, reply) => {
if (reply == 'OK')
res.sendResponse(body)
})
}
next()
}
})
}
app.get('/', midWare, (req, res) => {
// simulating a long process
wait(1000)
res.send('message from route /')
})
和上面的代码一样,我们只是改为用 Redis 替代。client.get(key,cb)参考传入的密钥从存储中检索储存的值。
采用Memcached
使用Memcached,我们将安装 memjs npm 模块:1
npm i memjs
并在我们的exp.js中配置它:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28const memjs = require('memjs')
const mc = memjs.Client.create()
const express = require('express')
const app = express()
const log = console
var midWare = (req, res, next) => {
const key = req.url
mc.get(key, (err, val) => {
if (err == null && val != null) {
res.send('from cache')
} else {
res.sendResponse = res.send
res.send = (body) => {
mc.set(key, body, { expires: 0 }, (err, reply) => {
if (reply == 'OK')
res.sendResponse(body)
})
}
next()
}
})
}
app.get('/', midWare, (req, res) => {
// simulating a long process
wait(1000)
res.send('message from route /')
})
与 Redis 相同,唯一改变的是客户端到 mc。 Redis 和 Memcached 具有几乎相同的 API,具有相同的功能。
结论
我们看到 expressjs 中的服务器端缓存是什么以及如何使用自定义代码配置一个。接下来,我们了解了如何使用 Redis 和 Memcached 将缓存添加到 expressjs 服务器。
缓存是我们加速应用程序尤其是服务器端应用程序的最佳优化技巧之一。许多人称它为不同的名称:memoization,这一切都归结为缓存的相同想法。
如果您对此或我应该添加、更正或删除的任何问题有任何疑问,请随时在下面发表评论并向我询问任何问题!谢谢 !!!